
It's a common practice for engineers to create unique repositories for different projects. This pattern of organizing and managing code projects is referred to as a polyrepo. There are good reasons you might want to use this approach, for example:
- It makes managing repository access control for different projects a lot easier
- Your team can rapidly implement and independently deploy various products
- It reduces complexity
A monorepo is the opposite. It's simply a repository that contains more than one project or application. That means a monorepo can contain a shared library, micro-services, and client applications in one repository.
While technically, these projects may be related, they can logically run independently of each other. In fact, they are mostly run by different teams, but the codebase is shared with everyone.
A monorepo allows teams to have a unified version control system (as a single source of truth) for their entire system. It makes code sharing across projects and libraries a lot easier.
More so:
- it simplifies dependency management across projects
- it improves collaboration
- allows for easier large-scale code refactoring
- allows you to see and understand how every part of the system is connected in one code base
- and simplifies your entire system deployment pipeline
As you can imagine, building a large monorepo code base for deployment can be a time-consuming process. Depending on the scale of your project, it could run into several minutes or even hours. That is not easily scalable.
That's where Turborepo comes in, especially if your tech stack is entirely JavaScript based.
Turborepo is a high-performance build system for JavaScript and TypeScript-based monorepos. It literally reduces your monorepo built time to milliseconds. It was built by Jared Palmer and acquired by Vercel in 2021.
So, what does Turborepo do to increase your monorepo build time?
Never recompute work that has been done before
Turborepo is designed to build your code faster, incrementally, and never to recompute work that has been done before using the following architecture:
Caching
Generally, caching is a transient data-storage mechanism that stores a subset of data so that further requests for data are served up faster than it's normally possible when accessing the same data from the primary storage location. Think Memcache and Redis.
Turborepo uses this approach to optimize your build system for speed and scale. Best of all, it allows you to cache your remote builds as well as your local build.
Local caching
When you run a build, Turborepo takes account of the metadata of that build and creates a cached record for it on your computer to ensure that it doesn't repeat that build if nothing changes in the related files.
Let's create a sample application to see this in action:
Run the following code on your Terminal to install and set up a fresh monorepo with Turborepo integrated.
$ npx create-turboThe prompt from that command will guide you to scaffold a basic monorepo containing two Next.js projects with shared ts-config, eslint, and a UI library.
Your project structure should look like so:
.
├── README.md
├── apps
│ ├── docs
│ │ ├── README.md
│ │ ├── next-env.d.ts
│ │ ├── next.config.js
│ │ ├── package.json
│ │ ├── pages
│ │ │ └── index.tsx
│ │ └── tsconfig.json
│ └── web
│ ├── README.md
│ ├── next-env.d.ts
│ ├── next.config.js
│ ├── package.json
│ ├── pages
│ │ └── index.tsx
│ └── tsconfig.json
├── package.json
├── packages
│ ├── eslint-config-custom
│ │ ├── index.js
│ │ └── package.json
│ ├── tsconfig
│ │ ├── README.md
│ │ ├── base.json
│ │ ├── nextjs.json
│ │ ├── package.json
│ │ └── react-library.json
│ └── ui
│ ├── Button.tsx
│ ├── index.tsx
│ ├── package.json
│ └── tsconfig.json
├── turbo.json
└── yarn.lockOnce that's completed, run a build or a lint task.
I'll run the lint task first;
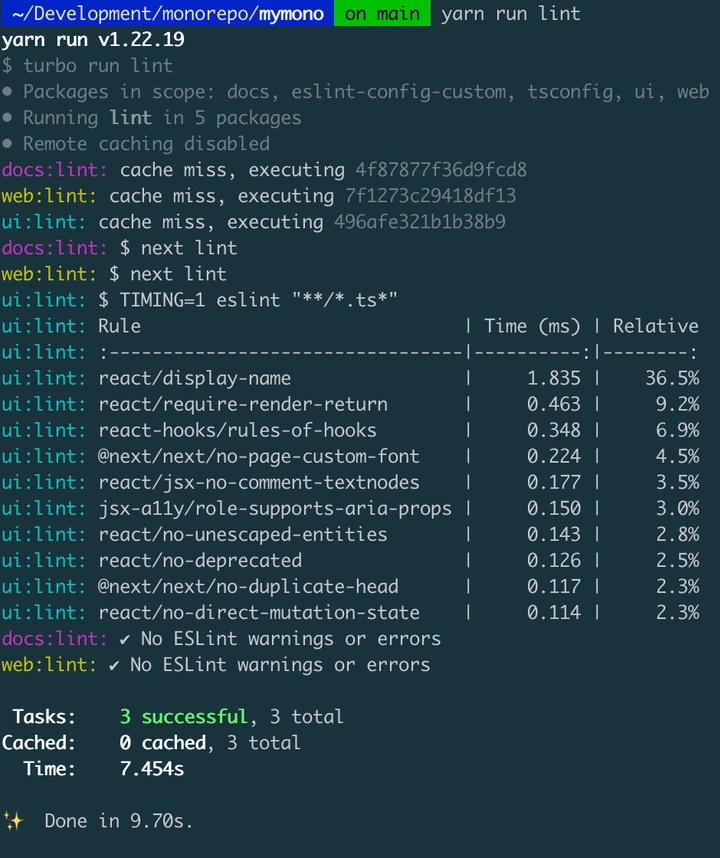
Notice that it took 7.454 seconds to run the first lint operation, and it says 0 cached, 3 tasks in total.
Now, if we run it again without changing anything in the files, the time it will take to process this operation is going to be way less. In my case, it took 669 milliseconds with the 3 tasks cached, as shown in the screenshot below;
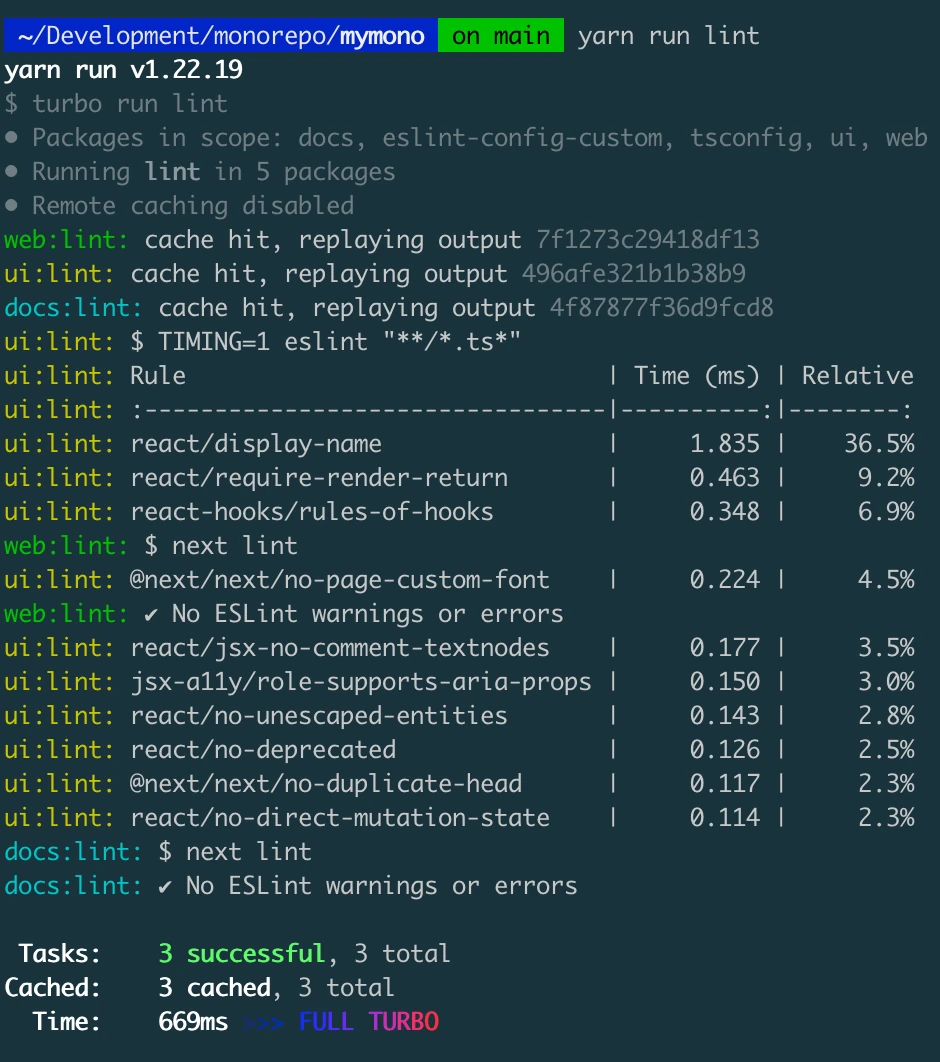
That's more than 99% time savings. So, what happened is that Turborepo cached the first lint task the first time it was run, and since we haven't updated the project files, it technically just replayed the previous lint result. This is the same thing that will happen for a build operation as well.
You can find the general cache log files in the node_modules directory ./node_modules/.cache/turbo. However, there are also app-specific caches saved in the app directory.
This works all nice, but when you create a build with your CI, you might not get the same experience since your CI has no record of any caches. It might take a long time each time you or anyone in your team create a deployment.
Remote Caching
To solve this problem, we use the Turborepo remote caching option, which stores your cache history in the cloud. The Turborepo partnership with Vercel allows them to securely store the result of your cache remotely on the Vercel servers.
Here is how to configure remote caching for your Turborepo setup. Run the following command:
You'll need to authenticate with Vercel before you can use the remote caching option with Vercel. You can create a free account on Vercel in case you don't have an account yet. Authenticate your Turborepo with your Vercel account by running the following command;
$ npx turbo loginNext, link your Turborepo to your remote cache:
$ npx turbo link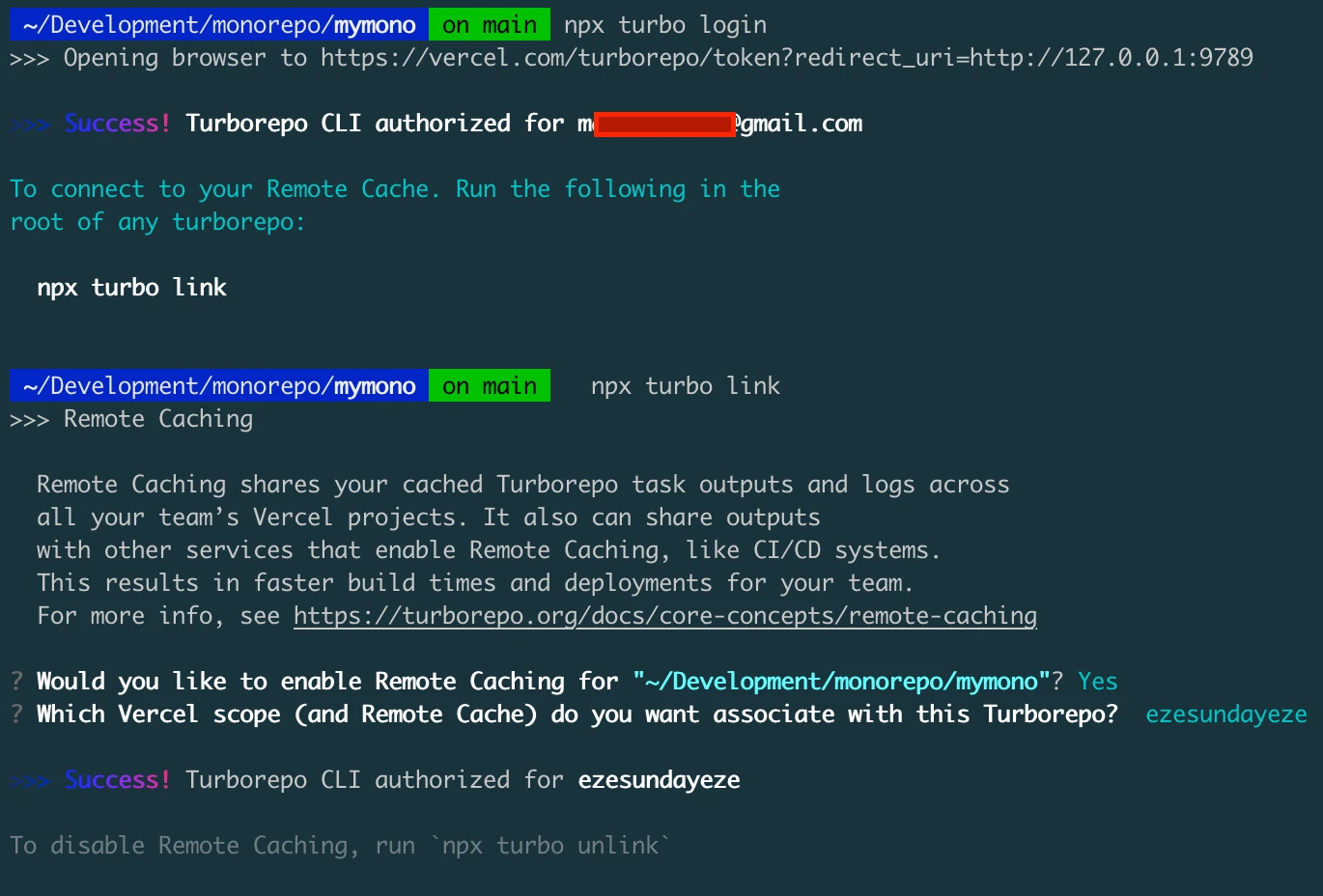
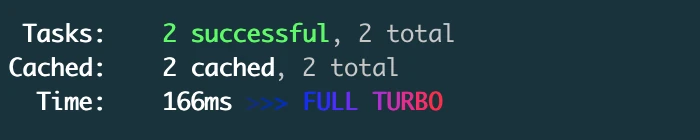
You can verify that it works by deleting your local Turborepo cache by running:
$ rm -rf ./node_modules/.cache/turboAnd then run the build again. You'll notice that it's still fast. For me, it took 166 milliseconds.
Interestingly, you can use your own custom remote caching host if you want as long as it complies with Turborepo's Remote Caching Server API.
Here is a sample command to help you set it up.
$ turbo run build --api="https://my-server.example.com" --token="xxx"You can refer to the docs for more details on how to set a custom remote caching for your project.
Multitasking
Turborepo can multitask and use your available CPU resources effectively in other to allow you to optimize your workflow for speed.

Take a look at the image above for a moment. There are two apps and a shared library running 3 tasks. This is a result of a task that was run with the yarn workspaces in a monorepo with the following command:
$ yarn workspaces run lint
$ yarn workspaces run test
$ yarn workspaces run buildYou'll notice that the tasks are running one after the other with lint going first, build follows, and it exits with the test.
This is an extremely slow process as each task needs to wait for the previous one. But with Turborepo's multitasking capability and how it understands your monorepo dependencies, it can schedule your tasks for maximum speed by understanding the dependencies between the tasks. It does this with the turbo.json configuration file in your root directory. See the example below:
{
"$schema": "https://turborepo.org/schema.json",
"pipeline": {
"build": {
"dependsOn": ["^build"],
"outputs": ["dist/**", ".next/**"]
},
"lint": {
"outputs": []
},
}
}With the turborepo configuration above, Turborepo will run as many tasks as possible in parallel over available CPUs. That means your task will run as shown below:
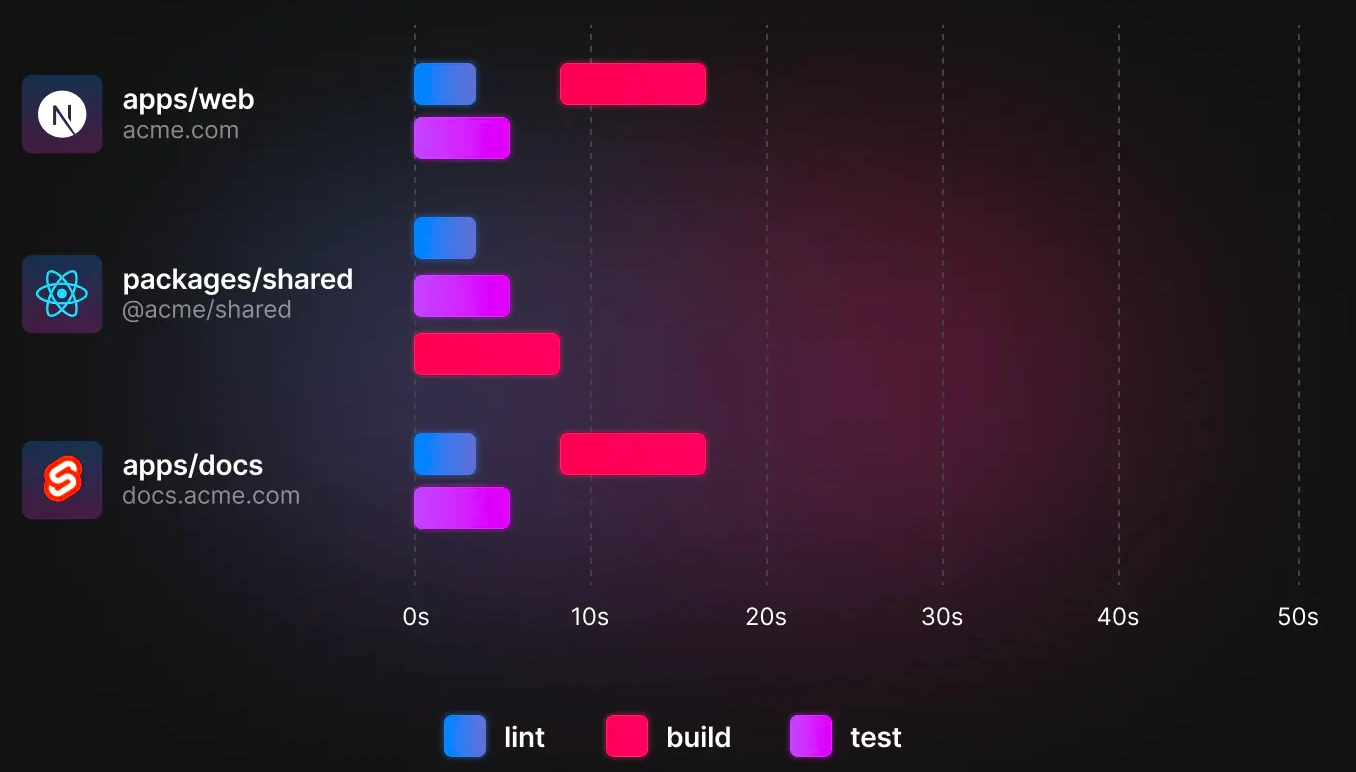
The way Turborepo understands the above task is that since both lint and test tasks do not have a dependency, they'll run immediately. In comparison, the build task for the shared directory runs next before the web and docs task since they both depend on the shared task because they have no dependsOn specified in the turbo.json file.
This is one of the ways Turborepo execution makes your build blazing fast.
Integration
Integrating Turborepo in your monorepo is straightforward. The best part with Turborepo is that you can integrate it into your existing monorepo and remove it anytime you want as far as your monorepo follows the workspaces architecture.
To integrate Turborepo into your monorepo, you'll first install Turborepo with your project package manager (yarn, npm, or pnpm):
$ npm install turbo -DThe turbo.json file is the configuration file for your Turborepo. This is where you'll define how you expect Turborepo to behave.
Here is an example of the turbo.json file and the pipeline:
{
"$schema": "https://turborepo.org/schema.json",
"pipeline": {
"build": {
"dependsOn": ["^build"],
"outputs": ["dist/**", ".next/**"]
},
"lint": {
"outputs": []
},
}
}That's all you need to integrate Turborepo into your existing monorepo, and you can remove this configuration if you don't want it anymore or want to test another monorepo tool. So, you don't even have to be worried about being locked in. There are a lot more configuration options to help you configure Turborepo as it best suits you. You should read the docs for more.
Conclusion
In the cause of this article, we've seen that Turborepo can speed up your monorepo build time exponentially, and it's easy to integrate into your workflow. Google and Microsoft use a whole bunch of tools to achieve the best result for their monorepos, as their monorepo source code runs into billions of files. If you are not Google and you use the monorepo project architecture design, Turborepo can give your project a significant boost and allow you to scale your codebase drastically.
